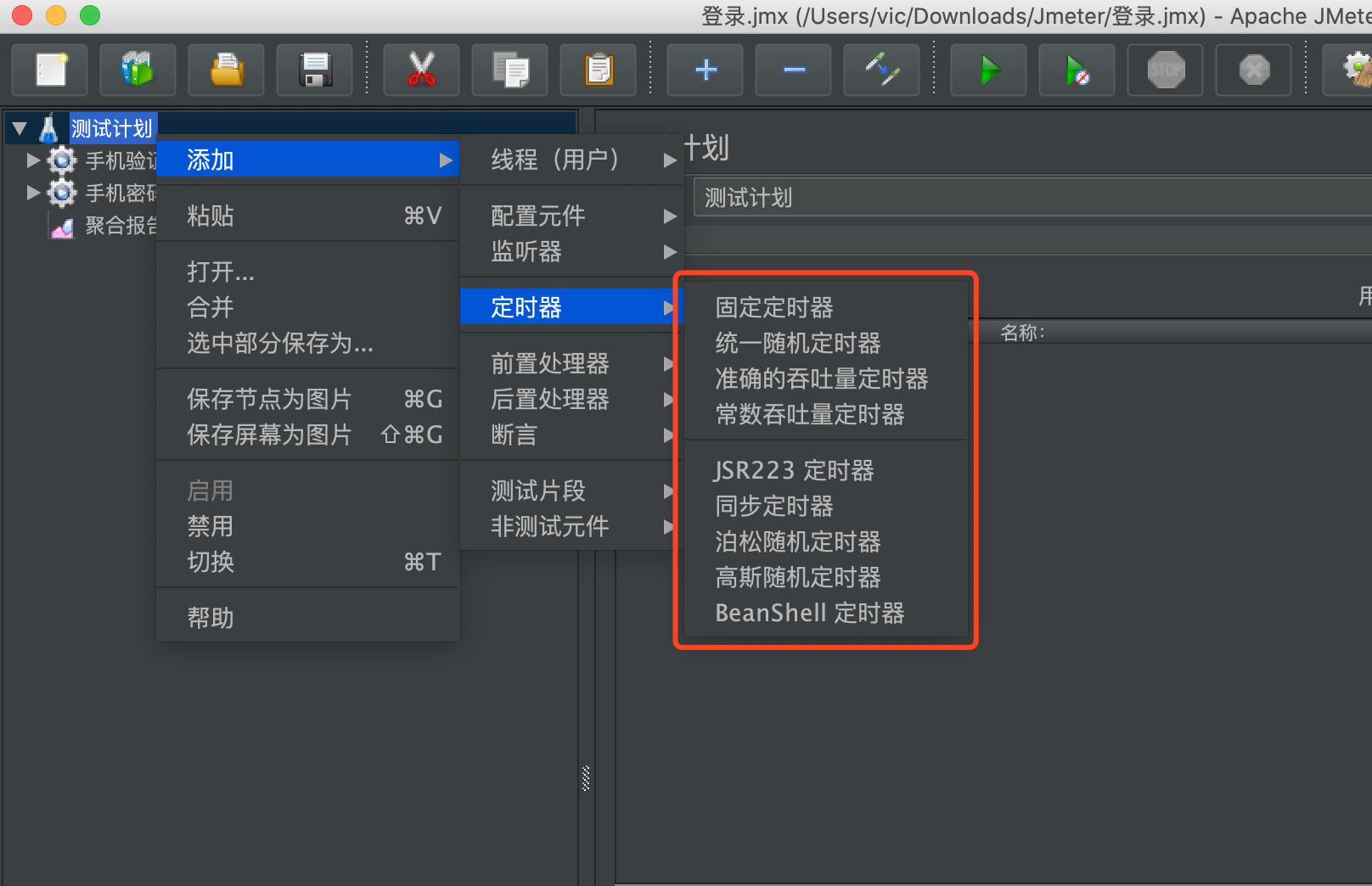
cron表达式详解
我们经常使用 cron 表达式来定义定时任务的执行策略,今天我们就总结一下 cron 表达式的一些相关知识。
cron表达式定义
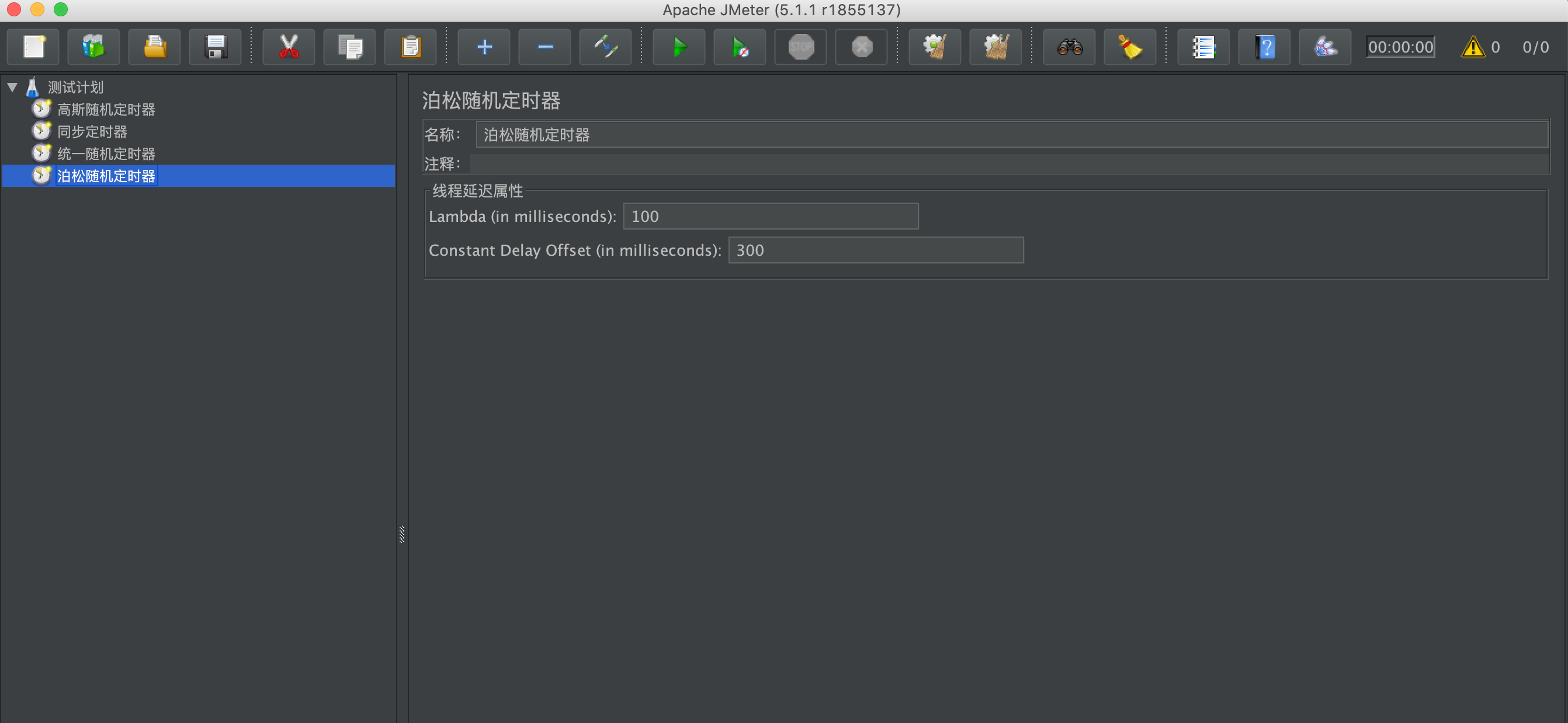
cron 表达式共有 7 个字段,包括 Seconds、Minutes、Hours、Day of mouth、Mouth,、Day of week,、Year,每一个字段代表一个含义
| Seconds | Minutes | Hours | Day of mouth | Mouth | Day of week | [Year] |
|---|---|---|---|---|---|---|
| 秒 | 分 | 时 | 天 | 月 | 周 | [年] |
其中Year是可选的
各字段的允许值及允许字符
| 字段名 | 允许值 | 允许的特殊字符 |
|---|---|---|
| Seconds | 0-59 | , - * / |
| Minutes | 0-59 | , - * / |
| Hours | 0-23 | , - * / |
| Day of mouth | 1-31 | , - * / ? L W |
| Mouth | 1-12 or JAN-DEC | , - * / |
| Day of week | 1-7 or SUN-SAT | , - * / ? L # |
| Year | 不填 or 1970-2099 | , - * / |
特殊字符的含义
* :匹配该字段允许的任意值,如果该字符在秒的位置处,表示每秒都会触发事件
- :表示范围,如果在分钟的位置处使用 5-20,即从第 5 分钟到第 20 分钟每分钟触发一次
/ :表示触发的起始时间和间隔时间,如果在分钟位置使用 5/20 ,即从第 5 分钟开始每隔 20 分钟触发一次(5、25、45分分别触发一次)
, :表示列出枚举值,如果在分钟位置使用 5, 20 ,即在第 5 和第 20 分钟各触发一次
? :只能用在 Day of mouth 和 Day of week 字段中,表示忽略任意值,因为这两个字段值可能会发生冲突,当其中一个值被指定后,需要忽略另一个来避免冲突。(比如20号不一定是周一)
L (last) :表示最后,在 Day of mouth 字段中表示”这个月最后一天”,在 Day of week 字段如果配合数字使用 ,如5L,表示”该月的最后一个星期四”
W (weekday) :表示最接近指定天的工作日(周一到周五),比如 15W,指最近接本月第15天的工作日,如果那天是周六,则在那周五即前一天触发事件,如果那天是周日,则在下周周一触发事件,如果那天是在周一到周五的范围内,则在当天触发。
LW(last weekday) :这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五。
# :只能用在 Day of week 字段中,表示该月的第几个周几,如 6#3 表示第3个周五(3 表示第 3 个,6 表示周五),如果指定日期不存在,事件不会触发
cron表达式例子
| cron表达式 | 含义描述 |
|---|---|
| 0 0 0 * * ? | 每天执行 |
| 0 0 12 * * ? | 每天12点触发 |
| 0 15 16 * * ? * | 每天16:15触发 |
| 0 0 10,15,16 * * ? | 每天10点,下午15点,16点触发 |
| 0 0/30 9-17 * * ? | 9-17时内,每30分钟触发一次 |
| 0 0 12 ? * WED/0 0 12 ? * 4 | 每个星期三12点 |
| 0 15 10 * * ? 2005 | 2005年的每天10:15触发 |
| 0 * 14 * * ?” | 每天14点到14:59期间的每1分钟触发 |
| 0 0/5 14 * * ? | 每天14点到14:59期间的每5分钟触发 |
| 0 0/5 14,18 * * ? | 每天14点到14:59期间和18点到18:55期间的每 5分钟触发 |
| 0 0-5 14 * * ? | 每天14点到14:05期间的每1分钟触发 |
| 0 10,44 14 ? 3 WED | 每年3月的星期三在14:10和14:44触发 |
| 0 15 10 ? * MON-FRI | 周一至周五的10:15触发 |
| 0 15 10 15 * ? | 每月15日10:15触发 |
| 0 15 10 L * ? | 每月最后一日的10:15触发 |
| 0 15 10 ? * 6L 2002-2005 | 2002-2005年的每月的最后一个星期五10:15触发 |
| 0 15 10 ? * 6#3 | 每月的第三个星期五10:15触发 |
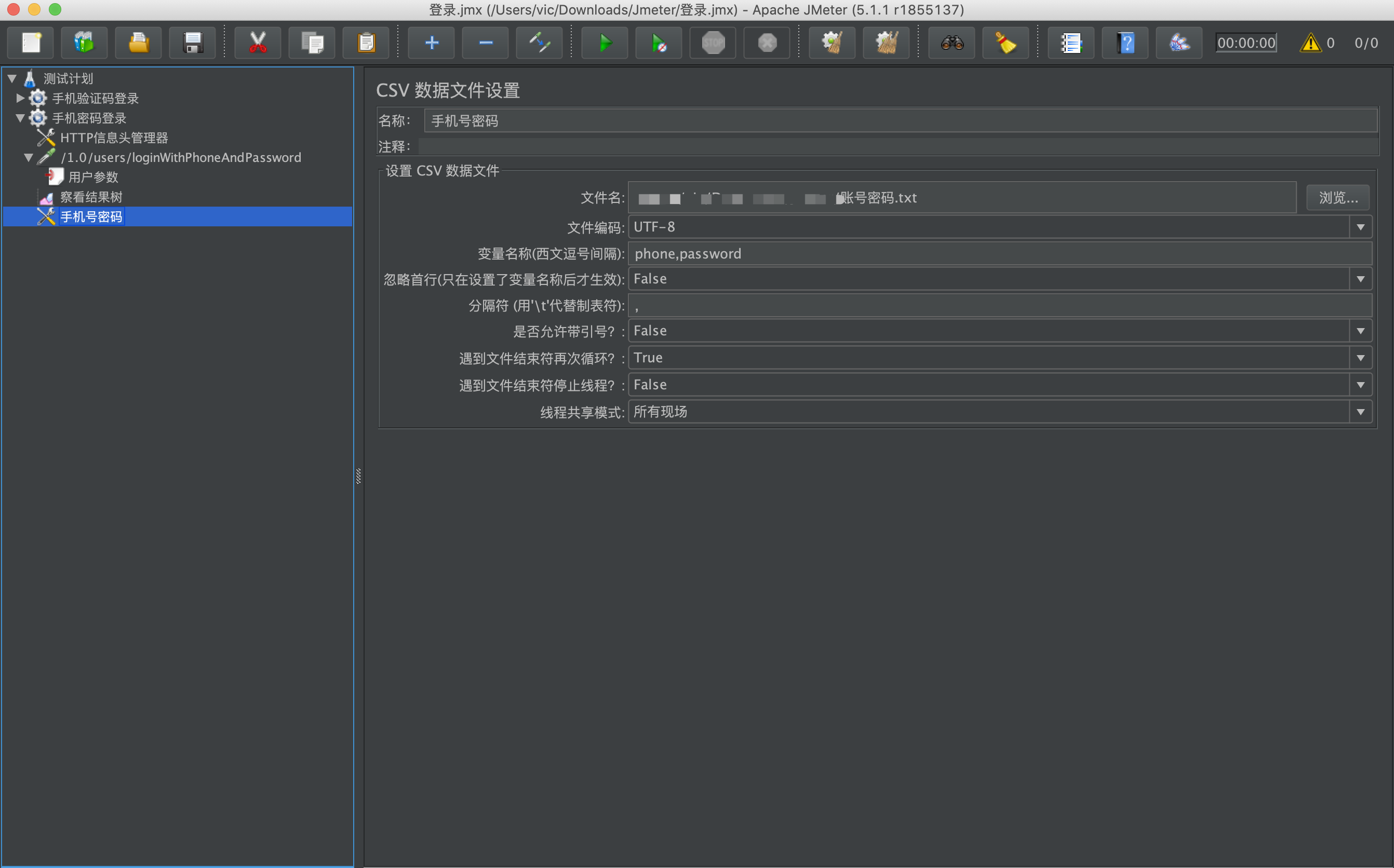
验证cron
- 正则表达式方法
1 | String regEx = "(((^([0-9]|[0-5][0-9])(\\,|\\-|\\/){1}([0-9]|[0-5][0-9]))|^([0-9]|[0-5][0-9])|^(\\* ))((([0-9]|[0-5][0-9])(\\,|\\-|\\/){1}([0-9]|[0-5][0-9]) )|([0-9]|[0-5][0-9]) |(\\* ))((([0-9]|[01][0-9]|2[0-3])(\\,|\\-|\\/){1}([0-9]|[01][0-9]|2[0-3]) )|([0-9]|[01][0-9]|2[0-3]) |(\\* ))((([0-9]|[0-2][0-9]|3[01])(\\,|\\-|\\/){1}([0-9]|[0-2][0-9]|3[01]) )|(([0-9]|[0-2][0-9]|3[01]) )|(\\? )|(\\* )|(([1-9]|[0-2][0-9]|3[01])L )|([1-7]W )|(LW )|([1-7]\\#[1-4] ))((([1-9]|0[1-9]|1[0-2])(\\,|\\-|\\/){1}([1-9]|0[1-9]|1[0-2]) )|([1-9]|0[1-9]|1[0-2]) |(\\* ))(([1-7](\\,|\\-|\\/){1}[1-7])|([1-7])|(\\?)|(\\*)|(([1-7]L)|([1-7]\\#[1-4]))))|(((^([0-9]|[0-5][0-9])(\\,|\\-|\\/){1}([0-9]|[0-5][0-9]) )|^([0-9]|[0-5][0-9]) |^(\\* ))((([0-9]|[0-5][0-9])(\\,|\\-|\\/){1}([0-9]|[0-5][0-9]) )|([0-9]|[0-5][0-9]) |(\\* ))((([0-9]|[01][0-9]|2[0-3])(\\,|\\-|\\/){1}([0-9]|[01][0-9]|2[0-3]) )|([0-9]|[01][0-9]|2[0-3]) |(\\* ))((([0-9]|[0-2][0-9]|3[01])(\\,|\\-|\\/){1}([0-9]|[0-2][0-9]|3[01]) )|(([0-9]|[0-2][0-9]|3[01]) )|(\\? )|(\\* )|(([1-9]|[0-2][0-9]|3[01])L )|([1-7]W )|(LW )|([1-7]\\#[1-4] ))((([1-9]|0[1-9]|1[0-2])(\\,|\\-|\\/){1}([1-9]|0[1-9]|1[0-2]) )|([1-9]|0[1-9]|1[0-2]) |(\\* ))(([1-7](\\,|\\-|\\/){1}[1-7] )|([1-7] )|(\\? )|(\\* )|(([1-7]L )|([1-7]\\#[1-4]) ))((19[789][0-9]|20[0-9][0-9])\\-(19[789][0-9]|20[0-9][0-9])))"; |
- CronExpression验证
这个方法需要引入quartz的jar包,然后只需要一行代码就可以验证了。
1 | CronExpression.isValidExpression(cron) |